
শৌর্য (বিজ্ঞান): আজ আমরা আলোচনা করবো, কৃত্রিম বুদ্ধিমত্তা বা আর্টিফিশিয়াল ইন্টেলিজেন্স নিয়ে। বোঝার চেষ্টা করবো — এই নিয়ে গবেষণার জগতে কী কী কাজ হচ্ছে। আমাদের সাথে আছেন কম্পিউটার সায়েন্স অধ্যাপক, ড: আবির দাস।
আচ্ছা, কম্পিউটার তো অনেকদিন ধরেই আছে। বিভিন্ন কম্পিউটার প্রোগ্রাম বেশ কিছু কাজকে স্বয়ংক্রিয় করার চেষ্টা করেছে। তাহলে হঠাৎ AI নিয়ে এত কথা হচ্ছে কেন?
আবির: AI বা বাংলায় যাকে বলে কৃত্রিম বুদ্ধিমত্তা, সেটাও কিন্তু অনেকদিন ধরেই রয়েছে। 1950-এর দশকে এই শব্দটার উৎপত্তি হয়। 1956 সালে একটা বিখ্যাত কনফারেন্স হয় ডার্টমুথ-এ এবং একটু পরে এই নিয়েই একটা রিসার্চ পেপার বেরোয়, মার্ভিন মিনস্কির। পেপারটা খুবই সুন্দর, পড়লে মনে হবে এখনকার অনেকগুলো শব্দই উনি ব্যবহার করেছেন সেই তখনকার যুগে। পেপারটার নাম ‘Step towards artificial intelligence’।
ওখানেই উনি AI-কে অনেকগুলো ভাগে ভাগ করেন। তারই মধ্যে একটা দিক আজকাল শোরগোল তুলেছে, সেটা হলো মেশিনের ‘learning’ বা শেখা।
সেই পেপারের বাকি প্রস্তাবগুলোকে অনেকে হয়তো ‘শেখা’ বলবে না; সেগুলো অনেকটা নিয়ম মেনে কাজ করার মতো। সেখানে কম্পিউটারকে নিজে থেকে শিখতে হয় না, আমরা নিয়মগুলো বলে দিই, হয়তো আমাদেরই শেখা কিছু নিয়ম, কম্পিউটার সেটা মেনে চলে। যেমন ধরো, কুকুরের থেকে বেড়ালকে আলাদা করে চিনতে হবে। আমরা বলে দিলাম, কুকুরের অমুক বিশেষত্ব থাকে, আর বেড়ালের তমুক বিশেষত্ব। এই নিয়মগুলো বলে দিলে, কম্পিউটার তার ভিত্তিতে সিদ্ধান্তে পৌঁছয়।
কুকুরের থেকে বেড়ালকে আলাদা করে চিনতে হবে। আমরা বলে দিলাম, কুকুরের অমুক বিশেষত্ব থাকে, আর বেড়ালের তমুক বিশেষত্ব। এই নিয়মগুলো বলে দিলে, কম্পিউটার তার ভিত্তিতে সিদ্ধান্তে পৌঁছয়।
এই সিদ্ধান্তটা কোনো সমস্যার সমাধান হতে পারে। যেমন ধরো কোনো একটা ছবিতে কী কী প্রাণী বা বস্তু আছে সেটা বুঝতে পারা। এটা ছিল পুরোনো আমলের AI (Good old fashioned AI)। কিন্তু কম্পিউটারকে উদাহরণের সাহায্যে যেভাবে শেখানো হয়, সেটা এসেছে পরে। অর্থাৎ, এখন আর বলে দিতে হয় না কার কী বিশেষত্ব — শুধু কোনটা কুকুর আর কোনটা বেড়াল, তার কিছু উদাহরণ দিলেই হয়। এই উদাহরণের ভিত্তি হলো ডেটা (data), যদি আরো চলতি শব্দ ব্যবহার করতে হয়। এই ডেটা বা তথ্যের সহজলভ্যতা আগে এতটা ছিল না।
এই নিয়ে আর একটু বিস্তারিত আলোচনা করা যাক। ছোট বাচ্চারা যেভাবে একদমই কম বয়সে একটা জিনিসের থেকে আরেকটাকে আলাদা করে চিনতে শেখে, তেমনই কম্পিউটারকেও শেখাতে হলে বিভিন্ন উদাহরণ দেখিয়ে বলতে হয় কোনটা কী। বলে দিতে হয়, এটা আপেল, ওটা কমলালেবু।
ছোট বাচ্চারা যেভাবে একদমই কম বয়সে একটা জিনিসের থেকে আরেকটাকে আলাদা করে চিনতে শেখে, তেমনই কম্পিউটারকেও শেখাতে হলে বিভিন্ন উদাহরণ দেখিয়ে বলতে হয় কোনটা কী। বলে দিতে হয়, এটা আপেল, ওটা কমলালেবু।
আমাদের মনে হতেই পারে, আগেও তো অনেক আপেল-কমলালেবুর ছবি ছিল, তাহলে এখন নতুন কী হলো? শুধু ছবি থাকলেই চলবে না, সেগুলো কোনটা কী, সেটাও বলে দিতে হবে। অর্থাৎ, লেবেল করা ছবি থাকতে হবে। এই পৃথিবীতে তো কত ধরনের জিনিস রয়েছে, সব বসে বসে চিহ্নিত করা কয়েকটা মানুষের পক্ষে আগে সম্ভব ছিল না। এছাড়া এত ছবিও ছিল না। প্রযুক্তি অতটা সস্তা ছিল না, ডিজিটাল ক্যামেরা ছিল না। আর শুধু ছবি থাকলেই চলবে না, সেটাকে ঠিক করে ব্যবহার করতে পারতে হবে। দশটা ছবি হলে সীমিত কম্পিউটিং ক্ষমতার মধ্যে থেকে তার থেকে কাজের জিনিস (features) বার করা যায়, কিন্তু সংখ্যাটা বেড়ে দশ লাখ হয়ে গেলে সেটা অসম্ভব হয়ে যায়।
2009-10 থেকে প্রযুক্তি দ্রুত উন্নত হতে শুরু করে। জিপিইউ বা গ্রাফিক্স প্রসেসিং ইউনিট (Graphics processing unit) বলে একটা হার্ডওয়্যারের নতুন ব্যবহার শুরু হয়। আগে এটা শুধু গেমারদের মধ্যে জনপ্রিয় ছিল। এটাকে যে কম্পিউটেশন-এর কাজেও লাগানো যায়, স্ট্যান্ডফোর্ড-এর প্রোফেসর এবং গুগল ব্রেন-এর বিজ্ঞানী এন্ড্রু এন (Andrew Ng) প্রথম এটা দেখান। আগেও এই নিয়ে গবেষণা হতো কিন্তু এটাই প্রথম এত বড় স্কেলে দেখানো হলো। অধ্যাপক এন একটা গ্রীষ্মের ছুটিতে গুগলে এসে এই কাজটা করেছিলেন — সেই বিখ্যাত বিড়ালের এক্সপেরিমেন্ট-টা [1]!
এনারই ছাত্র ছিলেন ইয়ান গুডফেলো (Ian Goodfellow), যার লেখা বই ডিপ লার্নিং-এ এখন প্রায় বাইবেলের মতো [2]। এনারাই জিপিউ ব্যবহার করে দেখান যে এর সাহায্যে আমরা একসাথে অনেকগুলো কম্পিউটেশন করতে পারি। যদি দশটা ছবি দেখানো হয়, সেই “দেখানো”-টাকে এমনভাবে ভাগ করা যায় যাতে দশটা দশটা করে কম্পিউটেশন আলাদা আলাদা প্রসেসর-এ একই সময়ের ব্যবধানে করা যায় (parallel computing)। ছোট করে বলা যায়, তথ্য সহজলভ্য হয় আর প্রযুক্তিও অনেক উন্নত হয়।

আর একটা কারণ বলা যায় — এটাকে chicken-and-egg সমস্যা (কোনটা আগে — মুরগি না ডিম?) না বলে chicken-and-egg সুযোগ (ডিম মুর্গি দুইয়েই লাভ) বলা যেতে পারে। প্রযুক্তি যেহেতু উন্নত আর সহজলভ্য হলো, তাই অনেকের এই বিষয় নিয়ে আগ্রহও বাড়তে শুরু করলো। অনেকে এমন ছিলেন যারা পদ্ধতিগুলো জানতেন কিন্তু তথ্যের সীমাবদ্ধতার কারণে অতটা এগোতে পারেননি, তারা দলে দলে এলেন, তাদের ছাত্ররা এল। অনেকে আসার ফলে কিছুদিনেই এই বিশাল পরিমাণ তথ্যভাণ্ডার নেড়েচেড়ে প্রয়োজনীয় বৈশিষ্ট্যগুলো খোঁজার নানান নতুন এবং অভিনব পদ্ধতি তৈরি হলো।
এই দুটোই AI-এর উত্থানের প্রধান কারণ — তথ্য এবং হার্ডওয়্যার-এর সহজলভ্যতা এবং প্রচুর বুদ্ধিমান মানুষের এই দিকে আসা।
এই প্রসঙ্গে একটা ছোট্ট জিনিস বলি। AI-এর হাইপ কিন্তু এর আগেও অনেকবার এসেছে। এ প্রসঙ্গে তোমরা হয়তো একটা শব্দ শুনে থাকবে, ‘AI winter’ বা AI শৈত্য। সেই শৈত্য কিন্তু এবারে এখনো অব্দি আসেনি। এবারের AI-এর হাইপ প্রায় 10 বছরের বেশি চলছে। বিশেষজ্ঞরা, যারা বহুদিন ধরে এই নিয়ে কাজ করছেন, তাদের মতে যে হারে AI-এর অগ্রগতি হচ্ছে, তারা আগে এমনটা দেখেননি। হয়তো আগে যে মাপকাঠিটা পেরোতে 30 বছর লাগতো, এখন 5 বছরেই সেটা হয়ে যাচ্ছে।
শৌর্যঃ মানে, সংক্ষেপে বলতে গেলে, AI-তে যে নতুন ব্যাপারটা শোরগোল ফেলেছে সেটা হলো শেখার বিষয়টা। কম্পিউটার আগেও নিয়ম মেনে কাজ করতে পারতো এবং এখনও অনেক ক্ষেত্রেই করে। কিন্তু এইটা আলাদা।
আমাদের আড্ডায় আজ কৌশিকদাও রয়েছে বিজ্ঞানের তরফ থেকে। তোমার কিছু প্রশ্ন থাকলে বলো কৌশিকদা।
কৌশিকঃ খুব ভালো লাগলো তোমার সাথে পরিচয় হয়ে। আমি তোমার গবেষণা নিয়ে বেশ কৌতূহলী। এই আড্ডার আগে আমি তোমার কাজ নিয়ে কিছু কিছু জিনিস দেখছিলাম। যতটা বুঝলাম তোমার কাজ ভিডিও নিয়ে, এটা নিয়ে কিছু বলো, তোমার এই বিষয়টা বেছে নেওয়ার পেছনে কী কারণ ছিল? আর কেমন গেছে এখনো পর্যন্ত গবেষণার সফর?
অবশ্যই। এই প্রসঙ্গে বলি, শৌর্য কিন্তু যাদবপুর ইলেকট্রিক্যাল ইঞ্জিনিয়ারিং-এ আমার ডিপার্টমেন্টে-এরই জুনিয়র। ও হয়তো পায়নি, কিন্তু আমরা বেশ কিছু অধ্যাপক পেয়েছিলাম, যাদের থেকেই আমার এই বিষয়ে আগ্রহ আসে।
এঁদের মধ্যে একজন ছিলেন অঞ্জন রক্ষিত স্যার। উনি পাঠক্রমের বাইরেও বিভিন্ন জিনিস শেখানোর চেষ্টা করতেন। আমাদের একটা ডিজিটাল সিগন্যাল প্রসেসিং-এর (digital signal processing) কোর্স ছিল। এর সাথে বিশ্ববিদ্যালয়ের পাঠক্রমে অন্তত দূরদূরান্ত পর্যন্ত ছবি প্রসেসিংয়ের কোনো সম্পর্ক ছিল না। সেই ক্লাসে একদিন উনি নিজের লেখা খুব ছোট্ট একটা প্রোগ্রাম নিয়ে এলেন। দেখালেন হিস্টোগ্রাম ইকুয়ালাইজেশন (histogram equalization) কীভাবে করতে হয় এবং এটা করলে ছবি-তে কী পরিবর্তন আসে। আর মজার ব্যাপার হলো, আমার কলেজের সময় (2003-2007), সেসময় কিন্তু ওভারহেড প্রজেক্টর ছিল না। উনি ওনার লেখা প্রোগ্রামটা প্রিন্ট করে এনেছিলেন।

তোমরা তখন কোন অ্যাপ্লিকেশনে(App) প্রোগ্রাম লিখতে? MATLAB কি ছিল সেসময়?
হ্যাঁ, তখন পুরোটাই MATLAB- এই।
তখন কি এআই(AI) এতটা গুরুত্ব পেয়েছিল?
না ততটাও নয়। তখন কম্পিউটার ভিসন-এর (computer vision) বেশিরভাগটাই ছিল সিগনাল প্রসেসিং-এর ওপর ভিত্তি করে। এখন যেমন সেটা লার্নিং বেসড (learning based) হয়ে গেছে, অর্থাৎ ডেটা থেকে শিখতে পারা (data driven), সেরকম তখন ছিল না।
যাইহোক, রক্ষিত স্যারের ওই কাজটা আমার মনে ধরেছিল। আমি বাড়িতে এসে নিজেও একটু চেষ্টা করে দেখলাম। কোনো একটা প্রোগ্রামিং ল্যাঙ্গুয়েজ দিয়ে ছবি খোলা এবং এডিট করার পুরো ব্যাপারটাই আমার কাছে বেশ মজাদার ছিল। মনে আছে, আমি প্রথম যে কোডটা লিখেছিলাম, সেটা খুবই সাধারণ একটা থ্রেশহোল্ডিং (thresholding) করার জন্য ছিল। তোমরা জানো একটা সাদা কালো ছবিতে 0 থেকে 255 অব্দি একটা পিক্সেল-এর ব্রাইটনেস (pixel brightness) হয়। সেরকম একটা সাদা কালো ছবি 128 থ্রেশহোল্ড ভ্যালুতে (threshold value) কী হয়, এটা করেই আমি বেশ মজা পেয়েছিলাম।

আমি সেসময় ডিজিটাল ইমেজ প্রসেসিংয়ের ওপর একটা বই কিনি, যেটা এখনো আমার সাথে রয়েছে — Gonzalez এবং Woods-এর Digital Image Processing। সেখান থেকে নিজেই একটু করে পড়ার চেষ্টা করি। কিন্তু ওই আর কী, ওই বয়সে নিজে নিজে পড়ে বোঝার সেই ক্ষমতাটা থাকে না।
শুরু থেকেই আমার হায়ার স্টাডির (higher study) ইচ্ছে ছিল। কিন্তু মাঝের দু-বছর বছর আমি ইন্ডাস্ট্রিতে চলে যাই। হয়তো অনেকেরই অভিজ্ঞতা আলাদা হবে, কিন্তু সেখানে আমার মনে হতে থাকে, এর আগের 16-17 বছরের পড়াশোনা করে কাটানো জীবনটাই অনেক ভালো ছিল। ইন্ডাস্ট্রিতে থাকতে থাকতেই আমি ঠিক করি যে আমি ডিজিটাল ইমেজ প্রসেসিং এই জাতীয় কিছু নিয়ে কাজ করবো। তারপর আসতে আসতে জানতে পারি যে কম্পিউটার ভিসন বলে শাখাটি রয়েছে।
নানা জায়গায় পিএইচডি গবেষণার জন্য অ্যাপ্লাই করা শুরু করি। ইউনিভার্সিটি অফ ক্যালিফোর্নিয়া, রিভারসাইড-এ আমি সুযোগ পাই। সময়টা 2010-এর আশেপাশে। তখনও কিন্তু কম্পিউটার ভিসনে এআই(AI)-এর অতটা জনপ্রিয়তা আসেনি।
2013 নাগাদ লার্নিং-এর ব্যাপারটা আসতে শুরু করে। এতদিনে লার্নিং-এর জন্য যা যা উপকরণ দরকার, সেগুলো চলে আসে — ডিজিটাল ক্যামেরা মোটামুটি সকলের হাতে চলে এসেছে, ইন্টারনেট-টাও সহজলভ্য হয়ে গেছে। তাই যদি প্রশ্ন আসে যে এতো জায়গা থাকতে কম্পিউটার ভিসন-এই কেন মেশিন লার্নিং-এর বিকাশ ঘটলো, তার উত্তর হলো — মেশিন লার্নিং-এর বিকাশের জন্য যা যা প্রয়োজন, এই কম্পিউটার ভিসন শাখাটাতে সেইসময় সেই সব কিছু ছিল।
UC রিভারসাইড-এ আমি ‘পার্সন রিআইডেন্টিফিকেশন’(Person re-identification) বলে একটা প্রবলেম নিয়ে কাজ করি। ধরো, কোনো সার্ভিলেন্স সিস্টেমে (surveillance system) অনেকগুলো ক্যামেরা আছে। দুটো আলাদা ক্যামেরা সবসময় আলাদা দিকেই দেখছে (non overlapping field of view)। মানে, একটা ক্যামেরা হয়তো কোনো ঘরের এক কোন দেখছে, আর একটা ক্যামেরা অন্য কোন দেখছে। এবারে অনেক লোকের ভিড়ে কিছু লোক ধরো ক্যামেরা 1-এর ক্ষেত্র থেকে বেরিয়ে ক্যামেরা 2-এর ক্ষেত্রে গেছে, কিছু হয়তো ক্যামেরা 5-এর ক্ষেত্রে গেছে, এইরকম। নতুন ক্যামেরা-তে আগের লোকগুলোকে আবার শনাক্ত করতে হবে। মাঝখানে একটা মিসিং ইনফরমেশন (missing information) আছে। এই লোকগুলোকে আমরা কী করে নতুন ক্যামেরার ভিডিওতে কীভাবে খুঁজে পাবো? এটা নিয়েই আমি প্রথম চার বছর কাজ করি।
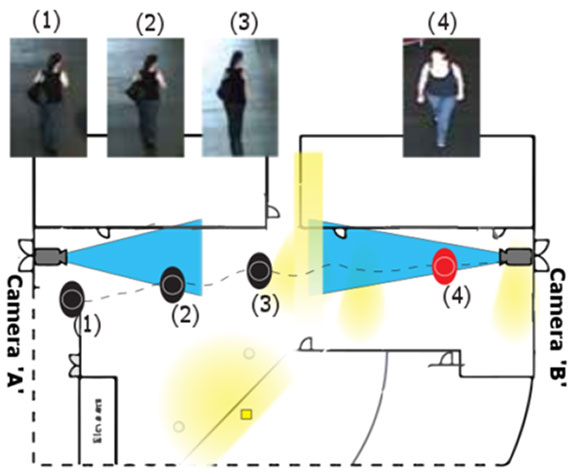
আচ্ছা এখানে মিসিং ইনফরমেশন-টা ঠিক কী?
ধরো একজন একটা ক্যামেরা থেকে বেরিয়ে অন্য কোথাও গেল। কোথায় গেল সেটা তো আমি জানতে পারছি না, যতক্ষণ না অন্য আর একটা ক্যামেরা তাকে দেখছে।
এখানে দুটো ক্যামেরা কিন্তু একই রকম ভাবে দেখছে না, একটা হয়তো মানুষটাকে সামনে থেকে দেখছে, আর একটা ক্যামেরা হয়তো পাশ থেকে দেখছে। হয়তো দুটো ক্যামেরার ক্ষেত্রের মধ্যে অনেকটা আলোর ফারাক রয়েছে — একটা হয়তো বাড়ির বাইরে, একটা ভিতরে। কোনো ক্যামেরা হয়তো বেশি জুম (zoom) করা। ফলত আমায় একটা ক্যামেরায় যেরকম লাগছে, অন্যটাতে আলাদা লাগবে।

তাই একজনকে দুটো আলাদা ক্যামেরার ফ্রেমে একই লোক বলে চিহ্নিত করাটা জটিল ব্যাপার।
আবার ধরো, দু-জন লোক আর দুটো ক্যামেরা রয়েছে। 1 নং লোকটিকে ক্যামেরা 2-তে 2 নং লোকের সাথে বেশি মিল লাগছে, এধরনের সমস্যাও আসতে পারে। এই গুলোকেই আমরা মেশিন লার্নিং-এর মাধ্যমে সমাধান করার চেষ্টা করি।
অর্থাৎ সমস্যাটা হলো, দুটো আলাদা ক্যামেরার ফুটেজ থেকে একই মানুষকে খুঁজে বের করা।
একেবারেই তাই। কিন্তু মনে রাখতে হবে, এখানে শুধু দুটো মানুষ আর দুটো ক্যামেরা নেই, প্রচুর ভিড় রয়েছে। তার মাঝে খুঁজে পেতে হবে।
এখনকার দিনে ফেসবুকে মানুষের মুখ যে ট্যাগ করা হয়, তাতে খুব একটা ভুল হয় না। শুনে লাগছে, আপনি যে পদ্ধতি নিয়ে কাজ করেছেন, এটা তারই একটা উন্নত সংস্করণ।
এখন এই ডিপ লার্নিং মেথড-টা আসার পরে পুরো মেশিন লার্নিং-এর ছবিটাই বদলে গেছে। এর প্রচন্ড শক্তিশালী ক্ষমতা হলো, এটা ডেটা-কে খুব ভালো ভাবে ব্যবহার করতে পারে। তবে এরও অনেক ত্রুটি আছে।
(চলবে)
প্রচ্ছদের ছবি: Gemini
উৎসাহী পাঠকদের জন্য
[1] অধ্যাপক এন-এর বিখ্যাত বেড়ালের এক্সপেরিমেন্ট-এর কথা ‘Google’-এর ব্লগে ওনারই ভাষায় এখানে রয়েছে — https://blog.google/technology/ai/using-large-scale-brain-simulations-for/ ।
[2] Ian Goodfellow-র লেখা deep learning-এর বাইবেল-টা এখানে পাওয়া যাবে — https://www.deeplearningbook.org/ ।