27-07-2026 15:16:01 pm
বিজ্ঞান - Bigyan
বাংলা ভাষায় বিজ্ঞান জনপ্রিয়করণের এক বৈদ্যুতিন মাধ্যম
An online Bengali Popular Science magazine
https://bigyan.org.in
মস্তিষ্ক বনাম AI
Link: https://bigyan.org.in/brain-vs-ai

বিজ্ঞান: আচ্ছা, এই ডীপ লার্নিং ব্যাপারটা কী?
আবির: আমরা দেখেছিলাম যে AI -এর একটা বড় অংশ হল শেখা (learning)। “ডীপ লার্নিং” এই শেখাটাকেই অন্য একটা জায়গায় পৌঁছে দেয়। “ডীপ লার্নিং” কথাটা জিওফ্রে হিন্টন (Geoffrey Hinton) এবং তার দল প্রথম প্রচারের আলোয় আনেন।
“ডীপ লার্নিং”-এর আগে যে শব্দটা ব্যবহার হতো, সেটা হলো “নিউরাল নেটওয়ার্ক” (neural network)। এ প্রসঙ্গে নিউরাল নেটওয়ার্ক কী, সেটা আমাদের একটু দেখে নেওয়া দরকার। নিউরাল নেটওয়ার্ক প্রযুক্তিখানা বেশ অনেক দিন থেকেই আছে। মোটামুটি ভাবে বলতে গেলে এটা অনেকটা মানুষের স্নায়ুতন্ত্রের মতো।
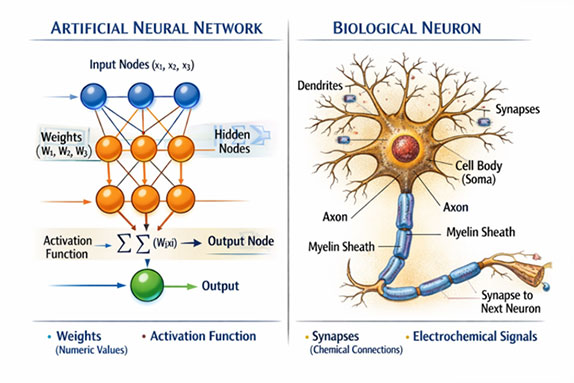
স্নায়ুতন্ত্রের একেকটা নিউরন (neuron) যেমন কিছু পরের নিউরনে তথ্য পাচার করে, একটা নিউরাল নেটওয়ার্কে এক একটা নোড (node) সেই গণনার এককের কাজটা করে। অর্থাৎ, এক একটা নোড-এ কিছু সহজ যোগ- গুণ-ভাগের মত গণনা সম্পন্ন হয় এবং গণনার উত্তরটা পরের নোড-এ চলে যায়। এই দ্বিতীয় নোড-টা কিন্তু অনেকগুলো আলাদা নোড-এর সাথে যুক্ত আছে। এইভাবে সমস্ত গণনার ফলাফল কোনো একটা নোড-এ এসে একত্রে একটা আউটপুট দেয়। এই একগুচ্ছ নোড-এ ইনপুট যদি হয় একটা ছবি, অনেকগুলো নোড-এর গণনার শেষে আউটপুট বেরোবে সেই ছবিতে কোন কোন বস্তু বা প্রাণী আছে।
এই পুরো ব্যাপারটায় এই যে একটা নোড-এ অনেকগুলো নোড এসে জুড়ছে, এটা অনেকটা আমাদের স্নায়ুতন্ত্রের মতো দেখতে লাগে বলে একে নিউরাল নেটওয়ার্ক বলা হয়। আসলে স্নায়ুতন্ত্র যেভাবে কাজ করে এটা হয়তো সেভাবে কাজ করে না। কীভাবে কাজ করে, সেটা নিয়ে এখনো গবেষণা চলছে।
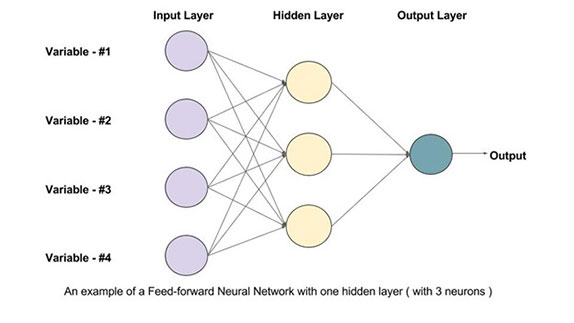
একটা নিউরাল নেটওয়ার্কের নোডগুলো স্তরে স্তরে (layer) সাজানো থাকতে পারে। এক একটা স্তরে বেশ কিছু নোড থাকতে পারে, যাতে একসাথে সমান্তরালে (in parallel) একাধিক গণনা হতে থাকে। ধরো, এরকম একটা স্তরে দশটা নোড রয়েছে। সেই দশটা নোড-এ গণনা হয়ে সবার উত্তরটা এর পরে একটা নোড-এ যাচ্ছে। সেরকম গ্রাহক নোড-ও ধরো দশটা রয়েছে। প্রথম দশটা নোড-কে আমি বলছি প্রথম স্তর (first layer), দ্বিতীয় দশটাকে দ্বিতীয় স্তর (second layer), এইরকম। এইরকম যখন অনেকগুলো স্তর এসে যাচ্ছে, সেটাকেই ডীপ লার্নিং (deep learning) বলে।
এতগুলো স্তরের সুবিধে কী? সুবিধে হলো, এর মাধ্যমে অনেক জটিল অপেক্ষক (function) সম্বন্ধে কম্পিউটার একটা আন্দাজ করতে পারে (এটাকে গাণিতিকদের পরিভাষায় বলে approximation)। শেষমেশ একটা নিউরাল নেটওয়ার্ক-এর কাজ হলো একটা অপেক্ষক কী হবে, সেটাকে অনুমান করা। ধরো, একটা নেটওয়ার্ক-এ ইনপুট হলো 

")

এটাই হলো আমাদের “লেবেল” করা “ডেটা”, যার কথা আগে বলেছিলাম। সেই ছবি চেনার উদাহরণ-টা ধরলে,
নেটওয়ার্কে অনেকগুলো স্তর থাকলে অনেক জটিল অপেক্ষকও তাকে শিখিয়ে দিতে পারো। জটিলতা কোথা থেকে আসে? ধরো, তুমি একটা মুখ চেনার সিস্টেম (face detection system) তৈরি করতে চাইছো। সেটা যদি এমন জায়গায় ব্যবহার হয় যেখানে প্রায় গবেষণাগারের মতো নিয়ন্ত্রিত পরিবেশ — অর্থাৎ হয়তো ছবিতে মুখ ছাড়া কিছু নেই, লাইটিং ভালো, পিছনের প্রেক্ষাপটের সাথে মুখটাকে সহজেই আলাদা করা যাচ্ছে — সেক্ষেত্রে হয়তো অল্পসংখ্যক নিউরন বা নোড-এর সাহায্যেই মুখ চিনতে শিখে যাবে। কিন্তু যদি সেটাকে বিভিন্ন পরিবেশে ব্যবহার করতে হয় — বিভিন্ন ধরনের আলো, কেউ হয়তো নিচে থেকে ছবি তুলছে কেউ উপর থেকে — সেক্ষেত্রে তোমার মুখ চেনার অপেক্ষক-টাকে এমন হতে হবে যেটা এতো রকমের ছবির বৈচিত্র্যকে সামলাতে পারে। সেইরকম জটিল অপেক্ষক শেখা সুবিধে হয় যদি তোমার নেটওয়ার্ক-এ অনেকগুলো স্তর থাকে। এটা যে সত্যি, সেটা অনেক কাঠখড় পুড়িয়ে প্রমাণও করা হয়েছে। এটাকে universal approximation theorem বলে।
আগে এত জটিল অপেক্ষক অনুমান করা সম্ভব ছিল না কারণ যে হার্ডওয়্যার-এ গণনা হচ্ছে, তাতে এতগুলো স্তরে গণনা করার ক্ষমতা ছিল না। তো, ‘ডীপ’ (deep) কথাটা এসেছে এই অনেকগুলো স্তরের উপস্থিতি থেকে। এরকম নয় যে কম্পিউটার খুব গভীরে গিয়ে কিছু শিখছে।
আগে এই এতগুলো স্তরে গণনা করা সম্ভব ছিল না, ফলে এত বিপুল ডেটা নিয়ে কাজ করা যেত না। এন্ডু এনের একটা বক্তৃতায় শুনেছি, ওনার পিএইচডি থিসিসে যে কটা ছবি ব্যবহার করা গেছিল প্রশিক্ষণ দিতে, সেটা আজকালকার দিনে হাসির বস্তু।
এবার আসি আমার কাজে। আমার পিএইচডি শেষ হওয়ার দিকেই ডীপ লার্নিং-এর প্রাদুর্ভাব হয়। সেজন্যই আমি এসব নিয়ে কিছুটা আগ্রহী হয়ে পড়ি। পোস্ট-ডক করার সময়, প্রথমে ইউনিভার্সিটি অফ ম্যাসাচুসেটস এবং পরে বস্টন ইউনিভার্সিটিতে ভিডিও নিয়ে কাজ করতে শুরু করি।
ভিডিও-কে বলা যায় একগুচ্ছ ফ্রেমের কালেকশন যেটাকে খুব তাড়াতাড়ি চালানো হয়। আমরা অনেকসময় শুনি 24 fps, 30 fps। এখানে fps হলো frames per second, অর্থাৎ এক সেকেন্ডে এতগুলো ফ্রেম পর পর তোমার সামনে দিয়ে চলে যাচ্ছে। ছবি নিয়ে কাজ করার সাথে যদি এর তুলনা করি, তাহলে ছবির শ্রেণিভাগের (image classification) মতো ভিডিওর শ্রেণিবিভাগও (video classification) করা যায়। ছবিতে যেরকম কোনো একটা ব্যক্তি বা বস্তুকে আমরা চেনার চেষ্টা করতাম, ভিডিওতে যেহেতু একটা সময়ের ব্যাপার চলে আসে, সেখানে কোনো একটা কাজের (activity) ভিত্তিতে শ্রেণিবিভাগ করা যায়।
কিংবা ভিডিওতে কোনো একটা কাজ শনাক্ত করাও (activity detection) একটা গবেষণার বিষয়। ধরো একটা লম্বা ভিডিও আছে। অবশ্য লম্বা বলতে এক-দুই মিনিটের ভিডিও ক্লিপের কথাই বলছি কারণ তার থেকে বেশি সামলানোর মতো হার্ডওয়্যার এখনো আসেনি। দশ মিনিটের ভিডিও-ও হয়তো সামলানো যায় কিন্তু সেক্ষেত্রে স্যাম্পলিং-এর হার (sampling rate) কমে যাবে — 30 fps পারবে না। যাইহোক, ধরো একটা দু-মিনিটের ভিডিও রয়েছে। মাঝখানে কেউ একজন হেঁটে যাচ্ছে কিন্তু পুরো সময়টা ধরে হাঁটছে না। কোন সময় হাঁটা শুরু হলো এবং কোথায় শেষ হলো, সেটা এই কাজ শনাক্তকরণের (activity detection) আওতায় পড়ে। এই ধরনের জিনিস নিয়ে আমি কাজ করেছিলাম শুরুর দিকে ডীপ লার্নিং-ভিত্তিক পদ্ধতি অবলম্বন করে।
এবার আসি আমার এখনকার কাজে। এখনকার দিনে নতুন যে হার্ডওয়্যারগুলো এসেছে — তাদের একটা খারাপ দিক হলো, এরা প্রচুর শক্তি খরচ করে। এটা পরিবেশের জন্যও খুব খারাপ। আগে যখন একটা হোম পিসি কিনতে, ভেবে দেখো UPS-গুলো কত Watt-এর হতো। খুব বেশি হলে 500 Watt হবে, সেটাও খুব বেশি হয়তো। এখন একেকটা ছোট জিপিইউ (GPU), যেটা ধরো রিসার্চের কাজে ব্যবহার হচ্ছে, সেটা 300 Watt শক্তি আত্মসাৎ করে। ইন্ডাস্ট্রিতে আরো বড়ো লেভেলের জিপিউ হাজারে হাজারে ব্যবহার হয়, সেগুলো আরো বেশি শক্তি খরচ করে। তাদের আবার ঠান্ডা রাখতে হয়। এই যে এতো গণনা হচ্ছে, তার ফলে অনেক তাপ সৃষ্টি হয়, তাই তাদের ঠান্ডা করতে কুলিং মেশিনের পেছনে প্রচুর শক্তি ব্যয় হয়।

আমরা চেষ্টা করছি এই পুরো ব্যাপারটায় শক্তি খরচের কার্যকারিতা (efficiency) বাড়াতে। এ নিয়ে মূলত দু-ধরনের কাজ করছি আমরা। ধরো তোমার কোনো একটা কাজ করতে বেশি গণনা করার দরকার নেই। যে উদাহরণটা একটু আগে দিলাম — ধরো তুমি একটা মুখ চেনার সিস্টেম বানাচ্ছ যেটা একটা নিয়ন্ত্রিত পরিবেশে কাজ করছে (লাইটিং ভালো, ইত্যাদি)। সেখানে অত জটিল অপেক্ষক বার করার দরকার নেই, তাই অতগুলো স্তর নিয়ে গণনা করারও দরকার নেই। এই যে জটিল গণনার দরকার নেই, এটা কম্পিউটার নিজে থেকেই বুঝতে পারবে, এমন ব্যবস্থা কি করা যায়? সমস্যাটা জটিল হলে কম্পিউটার আবার বেশি গণনায় ফেরত যেতে পারে। এই ব্যাপারটাকে যদি স্বয়ংক্রিয় করা যায়, অর্থাৎ কম্পিউটার যদি বুঝতে পারে যে কখন বেশি গণনা করবো এবং কখন কম, যেখানে বেশিরভাগই সহজ সমস্যা, সেখানে আমরা অনেক শক্তি বাঁচাতে পারি। এটার চেষ্টা চলছে।
আরেকটা হল … মুখ চেনার (face tagging) ব্যাপারটাকেই ধরো। এটা কিন্তু তুমি মোবাইলেই পাচ্ছ! মোবাইলে তো অত গণনা করার ক্ষমতা নেই। সেখানে অত শক্তিশালী জিপিউ নিয়ে ঘুরতে পারবে না, একটা ব্যাটারি নিয়েই কাজ করতে হবে। বা শুধু মোবাইল নয়, অনেক ক্লাউড-ভিত্তিক যন্ত্রও (cloud devices) কম ক্ষমতায় চলে। এই ধরনের কম ক্ষমতার যন্ত্রে (low power devices) কীভাবে এই ধরনের গণনা করা যায়, সেটাও একটা গবেষণার দিক।
বাহ! কাজটা নিঃসন্দেহে খুব আগ্রহের। এ নিয়ে একটা প্রশ্ন আমার মাথায় আসছে। আমরাও তো ভিডিওতে কী হচ্ছে বুঝতে পারি। কিন্তু আমাদের মস্তিষ্কের শক্তি ব্যবহার নিশ্চয় অনেক কম। এই তফাতটা আসছে কী করে? এ নিয়ে কি কোনো কাজ হয়েছে?
আমাদের মস্তিষ্ক কতটা শক্তি ব্যবহার করে তা নিয়ে বেশ কিছু কাজ হয়েছে। এবং সেটা সত্যিই অনেকটা কম। সাইকোলজিতে এ নিয়ে প্রচুর কাজ আছে।
আমার একান্তই নিজস্ব একটা মত আছে এই নিয়ে। ডীপ লার্নিং সিস্টেমগুলোকে অনেক ক্ষেত্রে গোড়া থেকে প্রশিক্ষণ দেওয়া হয়। সে কিছুই জানে না, তাকে শেখানোর চেষ্টা হচ্ছে। সেটা না করে একটা বিকল্প পদ্ধতি অবলম্বন করা যায়। এই নিয়ে দুটো ধারণা রয়েছে; প্রি-ট্রেনিং (pre-training) এবং ফাইন টিউনিং (fine tuning)। এগুলোর অর্থ হলো, একদম গোড়া থেকে শুরু না করে কিছুটা প্রশিক্ষিত মডেল-এর উপর কাজ করা।
ধরো তুমি একটা ফেস ডিটেকশন সফটওয়্যার (Face Detection Software) তৈরি করতে চাইছ, যা মানুষের মুখ চিনতে পারে। তুমি এমন একটা মডেল থেকে শুরু করতে পারো যাকে কিছু ছবি দিয়ে প্রশিক্ষণ দেওয়া হয়েছে। কিন্তু ছবিগুলো হয়তো সব মানুষের মুখের ছবি নয়। কুকুর, বেড়াল, আপেল, অনেক কিছুই হতে পারে। আমাদের একটা ধারণা হলো যে এরকম একটা মডেল যেহেতু কিছু ছবি দেখে রেখেছে, একে দিয়ে মুখ চেনানো অপেক্ষাকৃত সোজা। কারণ এর একটা ধারণা আছে “স্বাভাবিক” ক্যামেরায় তোলা ছবি কেমন হয়। সে বোঝে যে ছবির পিক্সেল-এর RGB-র মানগুলো কীভাবে পাল্টায়। যেমন, সে বোঝে যে একটা পিক্সেল লাল হলে, ঠিক পরের পিক্সেলটাই কমলা হয়ে যাবে না। এবং এই জ্ঞানটা সে ধরে রাখে। এবার যদি তুমি এই মডেলটাকে অনেকগুলো মানুষের মুখ দিয়ে প্রশিক্ষণ দাও তোমার ফেস ডিটেকশন-এর জন্য, তার জন্য কাজটা বোধহয় একটু সোজা হয়ে যায়।
প্রথম ধাপটাকে বলে প্রি-ট্রেনিং (pre-training)। অর্থাৎ, যে কাজের জন্য শেষে ব্যবহার হবে, সেই সংক্রান্ত তথ্যভাণ্ডার দিয়ে তাকে প্রশিক্ষণ দিচ্ছ না। আর পরের ধাপটাকে বলে ফাইন টিউনিং (fine tuning)। সে অলরেডি কিছুটা শিখে গেছে, তাকে আরেকটু প্রশিক্ষণ দেওয়া হচ্ছে।
আমার মনে হয় মানুষের মস্তিষ্কের ক্ষেত্রে এই প্রি-ট্রেনিং ব্যাপারটা হয় বলেই নতুন কিছু শিখতে অনেক শক্তি খরচ করতে হয় না।
মানে আমাদের মস্তিষ্ক এক ধরনের প্রি-ট্রেন্ড মডেল।
অনেকটা তাই।
আচ্ছা এই যে একটা ডীপ লার্নিং মডেল একটা সিদ্ধান্তে আসে, আমরা কি জানতে পারি কীভাবে সেই সিদ্ধান্তে আসে? এটা কি একটা ব্ল্যাকবক্স, যেখানে একটা সিদ্ধান্তের পিছনে কারণগুলো জানা যায় না? আমি না হয় একটা বেড়াল দেখে বললাম যে ল্যাজ দেখে বেড়াল মনে হচ্ছে বা কিছু, কিন্তু ডীপ লার্নিং মডেল-এর কেন কিছু মনে হচ্ছে, সেটা বলা সম্ভব কি? এ নিয়ে কিছু বলো তুমি।
একদম। একটা নিউরাল নেটওয়ার্ক-এর সিদ্ধান্তের পিছনে ব্যাখ্যা দেওয়ার চেষ্টাকে এক্সপ্লেনেবিলিটি (explainability) বলে। এ নিয়ে প্রচুর কাজ হচ্ছে। হওয়াটা দরকারও।
একটা বেড়ালের উদাহরণ নেওয়া যাক। আমরা মানুষেরা বেড়ালকে যেভাবে লেজ বা লোম দেখে চিনি, নিউরাল নেটওয়ার্ক সেভাবে নাও চিনতে পারে। সে যেভাবেই বুঝুক, সেটা বড় কথা নয়। কিন্তু কোনো নিউরাল নেটওয়ার্কের সিদ্ধান্তে যদি আমাদের বিশ্বাস করতে হয়, তাহলে তার কারণও জানতে হবে। ধরো তুমি একটা নিউরাল নেটওয়ার্ক-এর সিদ্ধান্তকে রোগ নির্ণয়ের (medical diagnosis) কাজে লাগাবে। যেমন, একটা রোগীর এক্স-রে প্লেট দেখিয়ে বলতে হবে প্রাণঘাতী কিছু দেখা যাচ্ছে কিনা। সেখানে যদি রোগীকে বলে দিই যে আমার অ্যালগরিদম (algorithm) বলছে তোমার অমুক রোগ হয়েছে, তাহলে সেটা হয়তো সেই মানুষটাকে খুব একটা ভরসা দেবে না। পরবর্তীকালে হয়তো আইনের দিক থেকেও আমাকে সমস্যায় পড়তে হতে পারে। মানুষকে যদি নিউরাল নেটওয়ার্ক-এর সিদ্ধান্তের উপর বিশ্বাস করাতে হয়, আমায় জানতে এবং জানাতে হবে কী কারণে আমি বলছি এই রোগটা হয়েছে।
পুরো ব্যাপারটা বুঝতে গেলে, আমার মনে হয়, আমাদের দুটো শব্দ জানতে হবে — জাস্টিফিকেশন (justification)এবং ইন্ট্রোস্পেকশন (introspection)। জাস্টিফিকেশন হলো, কোনো একটা সিদ্ধান্ত কেন নেওয়া হয়েছে, সেটা মানুষের মতো করে বোঝানোর চেষ্টা করা। যেমন ধরো, বিড়ালের লোম বা হাতির শুঁড় থেকে তুমি চিনতে পেরেছ প্রাণীগুলোকে, সেরকম কিছু। কিন্তু নিউরাল নেটওয়ার্ক হয়তো বোঝে অন্যভাবে। সেখানে, ইন্ট্রোস্পেকশন ব্যাপারটা চলে আসে। নিউরাল নেটওয়ার্ক হয়তো ল্যাজ-ট্যাজ দেখছে না। আমরা একটু আগে যে স্তর (layer) এবং নোড-এর (node) কথা বললাম, সেইটা ধরে বললে, বেড়াল দেখে হয়তো প্রথম স্তরের পাঁচ নম্বর নোড-এ এবং তৃতীয় স্তরের ছ-নম্বর নোড-এ বেশি উত্তেজনা দেখা যাচ্ছে। উত্তেজনা মানে হলো, সেই নোড-এ গণনার ফলটা অনেক বেশি। যখন হাতির ছবি দেখছে, হয়তো অন্য কোনো নোড-এ বেশি উত্তেজনা দেখা যাচ্ছে। হতে পারে, নিউরাল নেটওয়ার্ক-এর সিদ্ধান্তের পিছনে সেটাই সঠিক ব্যাখ্যা। এটা নিয়ে সত্যিই একটা বিতর্ক আছে — ইন্ট্রোস্পেকশন না জাস্টিফিকেশন, কোন ব্যাখ্যাটা বেশি জরুরী।
এই নিয়ে বেশ কিছু কাজ হচ্ছে। আমরাও এই নিয়ে একটা কাজ করেছিলাম। যে পদ্ধতিটা ব্যবহার করতাম, তার নাম দিয়েছিলাম রাইস (RISE – Randomised Input Sample for Explanation)। ধরো একটা AI সিস্টেম একটা ছবিতে একটা বিড়ালকে বেড়াল বলে চিনেছে। এবার তুমি সেই ছবিটা থেকে বিভিন্ন জায়গা এলোমেলো ভাবে মুছে দিলে। তারপর দেখছো, ওই অংশটা মুছে দেওয়ার ফলে কম্পিউটারের ছবিটিকে বিড়াল বলে চেনার সম্ভাবনা বাড়ছে না কমছে। যদি কোনো একটা অংশ সরিয়ে দিলে সম্ভাবনা বাড়ে, তাহলে যে অংশটা তুমি সরিয়ে দিয়েছ, সেটাকে বেড়াল-সদৃশ (cat-like) বলা যায়। সেই অংশটা বেড়াল বলে চেনার জন্য গুরুত্বপূর্ণ হওয়ার কথা। এইভাবে বেড়ালের বিভিন্ন অংশকে একটা নম্বর (score) দিতাম।
মানে তুমি বলতে চাইছো বেড়ালের ছবির সেই অংশগুলো অ্যালগরিদমটির ‘বিড়াল’ চেনার পেছনে বেশি অবদান রাখছে?
হ্যাঁ, ঠিকই বলেছ! আমি যদি আরো সহজ করে বোঝাই, ধরো তুমি কোনো একটা বাচ্চাকে একটা বিড়ালের ছবি দেখিয়ে চিনতে বলছো। একবার তুমি কানটা চেপে ছবি দেখালে, কখনো বা মুখটাই ঢেকে দিলে। বাচ্চাটা কখনো বলল চিনতে পারছে, কখনো বলল পারছে না। যখনই তুমি দেখবে যে সে কোনো একটা অংশ ঢেকে দেওয়ার পর আর চিনতেই পারছে না, তুমি বুঝবে বাচ্চাটা সেই জিনিসটা দিয়েই বেড়ালটাকে চিনতে পারছিল।
আমরা এই পদ্ধতিটাই ব্যবহার করেছিলাম। একটা বিড়ালের ছবিকে এইভাবে কিছুটা পাল্টে (আমরা বলতাম, perturb করে) আমরা নিউরাল নেটওয়ার্ক-কে প্রশ্ন করতাম — দেখোতো, বিড়াল হিসেবে চিনতে পারো কি না। যদি না পারে, তাহলে বোঝা যাবে মুছে দেওয়া অংশটা বোঝার জন্য জরুরি ছিল।
এ ধরনের পরীক্ষা সঠিকভাবে করতে গেলে একটা মানুষের তরফ থেকেও মূল্যায়ন দরকার। অর্থাৎ, কোনো একটা অংশকে বেড়াল-সদৃশ বলা হচ্ছে বটে কিন্তু একটা মানুষেরও কি তাই লাগছে? এইটাও দেখা দরকার। এটা আমাদের লোকবলের অভাবে খুব একটা করে ওঠা হয়নি। তবে এ নিয়ে প্রচুর কাজ হয়েছে। এই ধরনের কাজকে কীভাবে স্বয়ংক্রিয় করা যায়, সেটাও একটা ভাবার বিষয়। আমাদের এই কাজটা প্রচুর গণনাসাপেক্ষ ছিল। শুধুমাত্র দু-তিনটে জায়গা মুছে দিলেই চলবে না, অনেকবার এই ধাপটার পুনরাবৃত্তি করতে হবে। বিড়াল কিনা সেটা বোঝার জন্য ধরো তুমি একবার নিউরাল নেটওয়ার্ক-কে প্রশ্ন করলে, সেটায় কিছুটা সময় লাগে। কিন্তু সেই একই প্রশ্ন পাঁচ হাজারবার করলে সময় অনেক বেশি লাগবে। সেই সময়টা কীভাবে কমানো যায়, সেটাও একটা চ্যালেঞ্জ ছিল।
মোদ্দা কথা, এক্সপ্লেনেবিলিটি নিয়ে অনেক কাজ হচ্ছে। সাইকোলজি থেকেও বিভিন্ন চিন্তা ধার করে এটা নিয়ে কাজ করা হচ্ছে। যদিও এ নিয়ে আমি খুব একটা জানি না।
আর একটা জিনিস নিয়ে কাজ হচ্ছে, সেটাও আমি খুব একটা জানি না কিন্তু ভবিষ্যতে কাজ করার ইচ্ছে আছে। সেটা হলো কার্য-কারণ সম্পর্ক (causality) স্থাপন করা। জুডিয়া পার্ল বলে একজন নামকরা বিজ্ঞানী এই বিষয়ে কাজ করছেন।
আচ্ছা।
(এই লেখাটি মূল ইংরেজি থেকে বাংলায় অনুবাদ করেছেন স্বপ্ননীল জানা ও অনির্বাণ গঙ্গোপাধ্যায়।)
প্রচ্ছদের ছবি: Wikipedia
লেখাটি অনলাইন পড়তে হলে নিচের কোডটি স্ক্যান করো।
Scan the above code to read the post online.
Link: https://bigyan.org.in/brain-vs-ai