
লেখাটির প্রথম পর্বে আমরা দেখেছিলাম মানুষের জন্য আপাত সহজ কিছু কাজ করতে একটা যন্ত্রকে কতটা কাঠখড় পোড়াতে হয়। একটা ছবি চেনা কিংবা লিখিত শব্দের মর্মোদ্ধার করা, যেগুলো মানুষ অবলীলায় করতে পারে, সেগুলোই একটা যন্ত্রকে ধরে ধরে শেখানো প্রায় অসম্ভবের পর্যায়ে পরে। দ্বিতীয় পর্বে আমরা দেখলাম নিউরাল নেটওয়ার্ক-এর মাধ্যমে কিভাবে একটা যন্ত্র নিজে নিজেই শিখতে পারে। তবে তাকে শেখাতে অনেক উদাহরণ লাগে। এই পর্বে আমরা দেখবো ডীপ লার্নিং-এর মতো প্রযুক্তি কিভাবে এই প্রতিবন্ধকতা পার হলো।
ডীপ লার্নিং
কথা বলে নিজের বক্তব্য পেশ করা, অন্যের কথা শুনে বোঝা, আশপাশের অজস্র জিনিসকে চিনে নেওয়া, এগুলো আমরা ঠিক কিভাবে করি তা কয়েকটি স্পষ্ট নিয়ম দিয়ে বাঁধা প্রায় অসম্ভব বলে মনে হচ্ছিল সনাতন যুক্তিভিত্তিক এ আই তে। আশা ছিল এ এন এন এই জটিল সমস্যার সমাধান শিখে নেবে প্রচুর উদাহরণ থেকে। তার জন্য প্রয়োজন বহুস্তরীয় এ এন এন। কিন্তু শুধু ব্যাক প্রপাগেশন অ্যালগরিদম দিয়ে এমন বহুস্তরীয় নেটের সন্তোষজনক শিক্ষা হচ্ছিল না।
এসময় বেশ কিছু বছরের প্রচেষ্টার পর বহুস্তরীয় এ এন এন-কে কিভাবে শেখানো যেতে পারে তা বোঝা গেলো। শুরু হোলো ডীপ লার্নিং (deep learning) বা গভীর শিক্ষার অভিযান। নতুন পদ্ধতিতে ইনপুট আর আউটপুট-এর মাঝে প্রতিটি গুপ্ত স্তরকে আলাদা করে শেখানোর ব্যাবস্থা হল। আশা এই যে একেকটি গুপ্ত স্তর শিক্ষালাভের পর তার নিচের স্তরের তথ্যের বৈশিষ্ট্য বুঝে উপরের স্তরে সেই বার্তা পৌঁছে দিতে পারবে। এই শিক্ষা পদ্ধতি চলে সম্পূর্ণ তত্ত্বাবধান ছাড়াই। যেহেতু গোড়ার ইনপুট তথ্য কি তা বলে দেওয়ার কোনও তাড়না নেই, তাই যথেচ্ছ পরিমাণে তথ্য দিয়ে অনেক সময় ধরে এই শিক্ষা দেওয়া যেতে পারে। তারপর এই বৈশিষ্ট নিষ্কর্ষক স্তরগুলি একের পর এক সঠিক ক্রমে সাজিয়ে ও আউটপুট স্তর যোগ করে গোটা নিউরাল নেটটি বানানো হয়। এবার এই সম্পূর্ণ নেটটি উদাহরণের সাহায্যে নিজেদের সংযোগ ভারগুলি আরেকটু বেঁধে নেয় পূর্বোক্ত ব্যাকপ্রপাগেশন অ্যালগরিদম দিয়েই।
এই নতুন পদ্ধতির সাফল্য বেশ চমকপ্রদ। প্রথমে হাতে লেখা সংখ্যা চেনা, তারপর উচ্চারিত শব্দের থেকে কথা বুঝে নেওয়ার ব্যাপারে অনেক কম উদাহরণ থেকেও উল্লেখযোগ্য সাফল্য পাওয়া গেল। এমন এর আগে কখনও সম্ভব হয়নি। ২০১২-র মধ্যে উচ্চারিত শব্দের থেকে কথা বোঝার এই প্রযুক্তি এতই নির্ভরযোগ্য হয়ে উঠলো যে মোবাইল ফোনে প্রায় প্রতিটি অ্যাপ এর ব্যবহার শুরু করলো টাইপিং-এর বিকল্প হিসাবে।
ডীপ লার্নিং পদ্ধতিতে একেকটি গুপ্ত স্তরকে আলাদা করে শিখিয়ে তারপর প্রশিক্ষণপ্রাপ্ত স্তরগুলোকে জুড়ে নেটওয়র্ক তৈরী হয়।
পৃথকভাবে শেখানো স্তর সমৃদ্ধ নিউরাল নেট বিশেষ কার্যকরী হয় যখন উদাহরণের সংখ্যা প্রয়োজনের তুলনায় কম থাকে। পরে একটি নতুন ধরনের অতি সরল নিউরনের প্রচলন হয়, যেটি ডায়োডের মতন শুধু ধনাত্বক ইনপুটকে সরাসরি আউটপুট করে, বাকি আটকে দেয়। এই সরল নিউরনের বহুস্তরীয় নেটও বেশ তাড়াতাড়ি উদাহরণ থেকে শিখে ফেলে, আলাদা করে স্তরগুলিকে শিখিয়ে নিতে হয় না।
সি এন এন
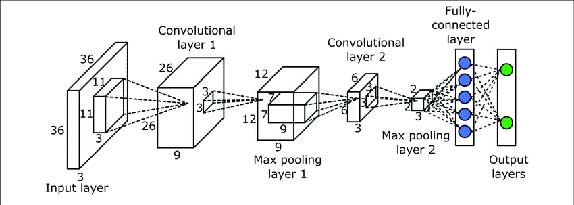
নব্বইয়ের দশক থেকে আরেক ধরণের নিউরাল নেট নিয়ে গবেষণা হচ্ছিল, তার নাম হল কনভলিউশনাল নিউরাল নেটওয়র্ক (convolutional neural network), বা সংক্ষেপে সি এন এন। এর প্রয়োগক্ষেত্র হল উচ্চারিত কথা, ছবি, ভিডিও, বা সাধারণভাবে কোনও সেন্সর থেকে আসা তথ্যের ধারার বিশ্লেষণ। এই ধরণের তথ্যের বিশেষত্ব হল এই যে এদের কাছাকাছি দুটি তথ্য স্থান বা সময়ে নিকটবর্তী এবং সেইজন্য তারা ঘনিষ্ঠভাবে সম্পর্কিত। যেমন, একটি উচ্চারিত কথার পাশাপাশি শব্দখন্ড মিলিয়ে একটি অর্থপূর্ণ শব্দের সৃষ্টি হয়, বা একটি ছবির নিকটবর্তী কয়েকটি চিত্রবিন্দু মিলিয়ে একটি জিনিসকে চেনা যায়। সনাতন স্তরপূর্ণ নিউরাল নেটে একটি স্তরের প্রতিটি নিউরন তার উপরের স্তরের প্রতিটি নিউরনের সাথে উপযুক্ত ভার দিয়ে সংযুক্ত। সি এন এন-এ কিন্তু এমন নয়। এর একটি স্তরের নিকটবর্তী কিছু নিউরন তার পরের স্তরের একটি নিউরনের সাথে সংযুক্ত। এই ধরণটির পুনরাবৃত্তি হয় এই দুই স্তরের সমস্ত সংযোগের মধ্যে।
শুধু তাই নয়, এই সংযোগের ভার-সমষ্টি দুটি স্তরের মধ্যে সমস্ত সংযোগের জন্য একই রাখা হয়। এইরকম ব্যাবস্থার কারণ হল কোনও প্যাটার্ন – সে একটি বিশেষ শব্দ হোক বা ছবি হোক – সময় বা স্থানে একটু এদিক ওদিক হলে কিছু যায় আসে না। এটি যেমন কোনও প্যাটার্ন চেনার জন্য বিশেষ কার্যকরী, তেমনই এতে খুব অল্প সংখ্যক সংযোগ ভারের মান স্থির করতে হয়। তাই এর শিক্ষা পূর্ণভাবে সংযুক্ত দুটি স্তরের থেকে অনেক সহজে সম্পন্ন হয়। একে বলে কনভলিউশন (convolution) স্তর।
একটা কনভলিউশনাল নিউরাল নেটওয়ার্ক-এ কনভলিউশন স্তরের পরে থাকে পুলিং (pooling) স্তর। কনভলিউশন স্তরের নিকটবর্তী বেশ কটি নিউরনের মধ্যে যার সক্রিয়তা সব চেয়ে বেশি, তার আউটপুট সরাসরি চলে আসে পুলিং স্তরের একটি নিউরনে। স্বাভাবিক ভাবেই পুলিং স্তরে নিউরনের সংখ্যা অনেক কম। এই কম সংখ্যক নিউরনের মধ্যে একটি বিস্তারিত ছবির বা তথ্যপ্রবাহের বৈশিষ্ট্য বা নির্যাস ধরা পরে।
পর পর এইরকম বেশ কিছু কনভলিউশন ও পুলিং স্তর দিয়ে ছবি বা তথ্য প্রবাহের একটি সংক্ষিপ্ত বিমূর্ত বিবরণ পাওয়া যায়। একদম শেষে কয়েকটি পূর্ণভাবে সংযুক্ত স্তর যোগ করে এই সম্পূর্ণ নেটওয়ার্কটিকে ব্যাক প্রপাগেশন অ্যালগরিদম দিয়ে অনেক উদাহরণের সাহায্যে শিক্ষা দেওয়া হয়। এইভাবে সি এন এন-এর বিশেষ গঠন ও বহুস্তরীয় নেটের জটিল সম্পর্ক শেখার ক্ষমতার সমন্বয়ে যে নেটটি তৈরি হল, তার কার্যকারিতার পরিচয় পাওয়া গেল ২০১২ র ইমেজনেট প্রতিযোগিতায়। এই প্রতিযোগিতায় প্রতিদ্বন্দ্বী অ্যালগরিদমগুলির চেয়ে সি এন এন যে স্পষ্টভাবে শ্রেয় তা প্রমাণিত হয় [১]। এরপর থেকে ছবি চেনা ও বোঝার ক্ষেত্রে সি এন এন হয়ে উঠলো অপরিহার্য। এছাড়াও উচ্চারিত বা লিখিত কথা বোঝার ব্যাপারেও এর সাফল্য অসামান্য।
আর এন এন
ডীপ লার্নিং-এর অভিযান শুরু হওয়ার অনেক আগেই আরেক ধরনের নিউরাল নেটওয়ার্ক নিয়েও কাজ হচ্ছিল। তার নাম হলো রিকারেন্ট নিউরাল নেটওয়ার্ক (recurrent neural network), বা সংক্ষেপে আর এন এন। যে সব তথ্যের মধ্যে সময় অনুযায়ী একটি ক্রমবিন্যাস আছে – যেমন উচ্চারিত শব্দখন্ডের বা লিখিত শব্দের শ্রেণী – বিশেষভাবে তাদের বিশ্লেষণের জন্যই এই নেটওয়ার্ক-এর সৃষ্টি।
আর এন এন-এর সংক্ষিপ্ত বর্ণনা খানিকটা এইরকম। ধরা যাক, সময়ের সাথে পরিবর্তনশীল একটি তথ্য শ্রেণীর কথা বলা হচ্ছে। সেই তথ্য শ্রেণীর মধ্যে একেকটি সময়ের ধাপে (time step) যে তথ্য রয়েছে সেটি এই নেটওয়ার্ক-এ ইনপুট হয় এবং তার ফলস্বরূপ একটি আউটপুট ঘোষিত হয়। এছাড়াও শেষ গুপ্ত স্তরের আউটপুটের একটি অংশ পরবর্তী সময়ের ধাপের নেটের প্রথম গুপ্ত স্তরে ইনপুট হয় (নিচের ছবিটি দেখো)। এইরকম আয়োজনের উদ্দেশ্য হল শ্রেণীর কোনও তথ্যকে বিচ্ছিন্ন ভাবে না দেখে তার পূর্ববর্তী তথ্যশ্রেণীর প্রেক্ষাপটে বিচার করা। উচ্চারিত কথা বা লিখিত বাক্যের মানে বোঝার জন্য এর খুবই প্রয়োজন।
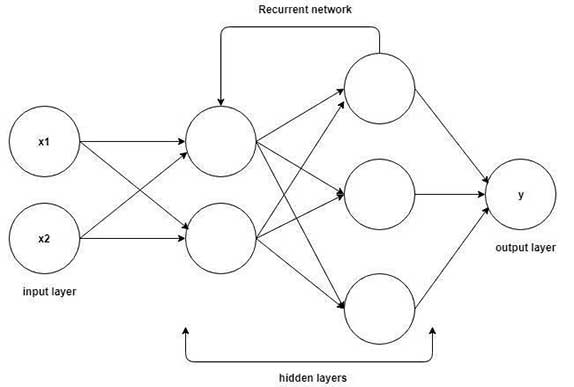
এর আরেকটি পার্শ্বপ্রতিক্রিয়া হল এই যে তথ্য শ্রেণীর একটি অর্থপূর্ণ অংশ – যেমন একটি বাক্য – ইনপুট হওয়ার পরে, শেষ গুপ্ত স্তরে এই অংশের একটি সম্মিলিত ছাপ ধরা থাকে। সেই ছাপ ব্যবহার করে একটি অন্য ভাষায় – যার বাক্যগঠনের রীতি অন্যরকম – একই কথা বলা যায়, অর্থাৎ অনুবাদ করা যায়। এর জন্য প্রয়োজন আরেকটি আর এন এন যার প্রথম ইনপুট হবে পূর্বোক্ত গুপ্ত স্তরের ছাপ, তারপর প্রত্যেকটি সময়ের ধাপে দ্বিতীয় ভাষায় একটি করে শব্দ আউটপুট করবে যতক্ষণ না বাক্য সম্পূর্ণ হয়। এই দুটি আর এন এন-কেই অবশ্য পৃথকভাবে অনেক উদাহরণ দিয়ে শেখাতে হবে, অনেক অনেক পূর্বে অনূদিত নথিপত্রর সাহায্য নিতে হবে।
একটি আর এন এন-কে পরের শব্দটি কি হতে পারে সে বিষয়েও শেখানো যেতে পারে অনেক অনেক নথিপত্র পড়িয়ে। কম্পিউটারে বা মোবাইলে আমরা যখন টাইপ করি, তখন সম্ভাব্য শব্দগুলি আমাদের সামনে এসে যায় এমনই একটি আর এন এন-এর সাহায্যে। এক্ষেত্রে আর এন এন আমাদের নিজস্ব লেখার ধরণ থেকে ক্রমাগত নিজেকে মানিয়ে নেয়, যাতে আরো নিখুঁতভাবে পরের শব্দটি ধরতে পারে।
এতো হল শুধুই বাক্য গঠন। একটি সি এন এন দিয়ে ছবির বিশ্লেষণ করে তার গুপ্ত স্তরের তথ্যকে একটি আর এন এন এ ইনপুট করে ছবিটির একটি ভাষায় বর্ণনা পাওয়া যেতে পারে। এর জন্য অবশ্য আর এন এন-কে উদাহরণের সাহায্যে শেখাতে হবে কি করে সি এন এন-এর গুপ্ত স্তরের তথ্য থেকে ছবিটিকে ভাষায় বর্ণনা দেওয়া যেতে পারে। কিন্তু সব মিলিয়ে এর ফলটি বেশ চমকপ্রদ।
ডিপ লার্নিং এর প্রভাব
নিউরাল নেটওয়ার্ক সম্বন্ধে এত বিস্তারিত আলোচনার কারণ হলো এই যে সম্প্রতি এ আই-এর যত সাফল্য এসেছে তার প্রধান স্তম্ভ ডীপ লার্নিং প্রযুক্তি। নেটওয়ার্ক গভীর ও প্রয়োজনমত বিস্তারিত হলে যে ইনপুট এবং আউটপুটের মধ্যে প্রায় যে কোনও বাস্তব সম্পর্ক শিখে ফেলা যায়, এটিই হল এই প্রযুক্তির প্রধান বক্তব্য। তীব্র গতিসম্পন্ন গ্রাফিক্স প্রসেসর ইউনিটের ব্যবহার এই শেখার পর্বটি সময়ের দিক থেকে সহনীয় করে তোলে। বলা যায়, ডীপ লার্নিং-ই আমাদের দৈনন্দিন জীবনে এ আই-এর ছোঁয়া এনেছে – বিশেষ করে মোবাইলের বিভিন্ন অ্যাপের মাধ্যমে।
তবে সব সময় যে শুধু ডীপ লার্নিং দিয়েই সমস্যার সমাধান হয় তা নয়, চিরাচরিত এ আই-এর যুক্তি, তর্ক ও অনুসন্ধানের উপরও প্রায়ই ভরসা করতে হয়। এখন কনভারসেশনাল এ আই, অর্থাৎ কম্পিউটারের সাথে কথোপকথনের প্রযুক্তি নিয়ে অনেক কাজ হচ্ছে। নিউরাল নেটওয়ার্ক অনেকটা যান্ত্রিক ভাবে উচ্চারিত বা লিখিত ভাষাকে ব্যবহার করে। তাতে আমরা উচ্চারিত কথার থেকে লিখিত শব্দমালা, বা লিখিত শব্দমালা থেকে উচ্চারিত কথা পেতে পারি, এমনকি এক ভাষা থেকে অন্য ভাষায় অনুবাদও পেতে পারি। কিন্তু ঐ শব্দমালার মধ্যে অন্তর্নিহিত ভাব কম্পিউটার সহজে ধরতে পারেনা। তার জন্য বাক্যের গঠন, শব্দের অর্থ, ইত্যাদি নিয়ে যুক্তি ও অনুসন্ধানের প্রয়োজন হয়। তাই কম্পিউটারের পক্ষে মানুষের সাথে টানা কথোপকথন করা বেশ কঠিন। গুগল হোম বা অ্যামাজনের ইকো অথবা বিভিন্ন ওয়েবসাইটের চ্যাটবট প্রায়ই কথার প্রসঙ্গ ধরতে না পারলে হতভম্ব হয়ে যায়।
রিইনফোর্সমেন্ট লার্নিং
মানুষের বুদ্ধির প্রকাশ শুধু চোখে দেখা আর কথা শোনার মধ্যেই নয়, হাত ও পায়ের চালনা করে সূক্ষ্মাতিসূক্ষ্ম কাজ করা, যেমন হাঁটা, দৌড়ানো, খেলাধুলা ইত্যাদির মধ্যেও হয়। এসবের আড়ালে প্রছন্ন আছে এক ধরণের নিয়ন্ত্রণ ক্ষমতা, যা কিছুটা সহজাত আর কিছুটা শেখা। এও একধরণের বুদ্ধি, যেটি যুক্তিগ্রাহ্য নয়, অনেকটা অবচেতন স্তর থেকে কাজ করে।
এইরকম ক্ষমতা যন্ত্রকে প্রদান করা কিন্তু মোটেও সহজ নয়। রোবটের প্রতিটি অঙ্গের জাড্যের অনুমান করে, গতিবিদ্যা এবং নিয়ন্ত্রণ শাস্ত্রের সূত্র মেনে তার প্রতিটি মোটরে কি পরিমাণে বিদ্যুৎ প্রবাহ হওয়া উচিত তার অনেক হিসাব কষেও একটি রোবটকে দিয়ে সুস্থির ও নিশ্চিতভাবে চলাফেরা করানো একটি বিরাট চ্যালেঞ্জ। এক্ষেত্রে সূত্রের উপর সম্পূর্ণ নির্ভর না করে ক্রমাগত শিক্ষার মাধ্যমে রোবট এই দক্ষতা অর্জন করতে পারে। এই ব্যাপারে নিউরাল নেটওয়র্ক ও ডীপ লার্নিং খুবই প্রাসঙ্গিক। কিন্তু তার সঙ্গে আরেকটি ধারণাও মনে আসে – তা হল রিইনফোর্সমেন্ট লার্নিং (reinforcement learning) [২]।
এটি এমন একটি শিক্ষা পদ্ধতি যাতে রোবট কিছুটা তার পূর্ব অভিজ্ঞতার ভিত্তিতে এবং কিছুটা এলোমেলো ভাবে তার কর্ম নির্ধারণ করে। কোন কর্মের কেমন ফললাভ হচ্ছে সেই অনুযায়ী তার অভিজ্ঞতার সংশোধন হতে থাকে এবং ভবিষ্যতে কর্ম নির্ধারণের ধরণটিও পালটে যায়। এইভাবে ক্রমেই রোবট আরও আরও দক্ষ হয়ে ওঠে। এটি শিক্ষার খুবই কার্যকরী একটি পদ্ধতি, এবং আমরা এই ভাবেই অধিকাংশ দক্ষতা অর্জন করি। শুধু এতে শিক্ষার সময় লাগে প্রচুর। তাই সাধারণত প্রাথমিক কিছুটা শিক্ষা দেওয়া হয় সিমিউলেশন-এ (simulation), অর্থাৎ কমপিউটারে একটি মডেল বানিয়ে। তারপর বাস্তব জগতে রোবট সেই অভিজ্ঞতার ভিত্তিতে কাজে নেমে পড়ে এবং ক্রমশ কাজের মধ্যে ভুল ভ্রান্তির থেকে শিখে দক্ষ হয়ে ওঠে। এই শিক্ষা কোনরকম তত্ত্বাবধান ছাড়াই চলতে থাকে। ভুল থেকে রোবটের যাতে কোনও ক্ষতি না হয় সেজন্য কিছু সাবধানতা অবলম্বন করতে হয়।
এ আই এর ভবিষ্যৎ
আমাদের পরিবেশে এ আই-এর একটি গুরুত্বপূর্ণ অবদান হবে ড্রাইভার-বিহীন গাড়ি। ক্যামেরা ও রেঞ্জ সেন্সর দিয়ে আশপাশটা বুঝে নিয়ে এই গাড়ি নিজেই নিজের পথ দেখে এগিয়ে চলে। শুধু গন্তব্যস্থানটি বলে দিতে হয়। এর প্রযুক্তি প্রায় প্রস্তুত। একটু সীমিত ভাবে চালিয়েছেও এমন গাড়ি Google আর Uber। আরো কিছুটা সময় লাগবে একে আরও নির্ভরযোগ্য করে তোলার জন্য। এতে একটি বিশেষ সুবিধা হল এই যে প্রত্যেকটি যন্ত্রচালিত গাড়ি ট্র্যাফিকের নিয়ম মেনে সার্বিক নিরাপত্তার কথা ভেবে চলে, তাই দুর্ঘটনার সম্ভাবনা যায় অনেক কমে।
এর পাশাপাশি তৈরি হচ্ছে স্বয়ংক্রিয় শিল্প রোবট, যা তার কর্মক্ষেত্রের মধ্যে সব কিছু দেখে শুনে বুঝে ঠিক করে কিভাবে আদিষ্ট কাজটি সুসম্পন্ন করবে। অনেক সময় মানুষের সাথে হাত মিলিয়ে তাকে কাজ করতে হয়। সেক্ষেত্রে মানুষ সহকর্মীর নিরাপত্তার প্রতিশ্রুতি দিতে হয় রোবটকেই। এমন নমনীয় রোবট তৈরি হচ্ছে যা কাজের প্রয়োজনে যথেষ্ট বলপ্রয়োগ করতে পারে, কিন্তু মানুষ সহকর্মীর সাথে অপ্রত্যাশিত কোনও সংঘর্ষ হওয়ার পূর্বমুহূর্তে নিজেকে নরম করে ফেলে। এ আই-এর গোরার চিন্তাধারাগুলির উদ্ভব হয়েছে কম্পিউটার আবিষ্কারের কয়েক দশকের মধ্যেই। পরে তারা অনেক পরিমার্জিত ও পরিশোধিত হলেও এ আই-এর সাম্প্রতিক সাফল্যের মূলে আছে প্রধানত উন্নতমানের সেন্সর, কম্পিউটারের সামান্য আয়তন, গণনার তীব্র গতি, ও স্মৃতি ধারণের অসীম ক্ষমতা। মোবাইলের মাধ্যমে এ আই আজ আমাদের সবার জীবনকে বিভিন্ন মাত্রায় সমৃদ্ধ করেছে। কম্পিউটার যেমন ক্রমাগত ছোট ও দ্রুততর হয়ে চলেছে, তাতে আমাদের দৈনন্দিন ব্যবহারের অনেক জিনিসের মধ্যেই তার অনুপ্রবেশ অবশ্যাম্ভাবি। পঞ্চম প্রজন্মের ইন্টারনেটে এর ব্যাবস্থাও আছে। এর পরিণতি কেমন হবে তা কল্পনা করা বেশ কঠিন। সব কার্যকলাপের মধ্যে অজস্র কম্পিউটার চিপ্স ও সেন্সর আমাদের ঘিরে থাকবে, সাহায্য করবে কাজ সুসম্পন্ন করতে। এতে কি আমাদের শ্বাসরোধ হয়ে আসবে? এখন এমন মনে হলেও, সময়ে হয়ত আমরা তার সাথে তাল মিলিয়ে চলার ক্ষমতা ও উৎসাহ পাবো।

শেষ পর্যন্ত এ আই এর থেকে আমরা কি চাইতে পারি? হিউম্যানয়েড রোবট, অর্থাৎ মানুষের মত চেহারার রোবট, যে আমার সঙ্গী হয়ে বিভিন্ন ব্যাপারে তথ্য বা পরামর্শ দিতে পারে, মুষড়ে পড়লে উৎসাহ দিতে পারে, অথবা কাজ করে সাহায্য করতে পারে। এর প্রথমটি অনেকটাই আয়ত্তের মধ্যে এসে গেছে। গুগল অ্যাসিস্টেন্ট, অ্যামাজনের অ্যালেক্সা, অ্যাপলের সিরি, বা মাইক্রোসফ্টের কোর্টানা এর পূর্বসূরি, যদিও এরা কম্পিউটারের আড়ালে থেকে কথা বলে। মানুষের মতন চেহারায় গুছিয়ে কথা বলে এমন রোবটও হয়েছে – যেমন অ্যামেরিকার সোফিয়া, জাপানের এরিকা ইত্যাদি। এদের ক্ষেত্রে কথার বিচক্ষণতার চেয়েও বেশি গুরুত্বপূর্ণ হল কথা বলার মানুষসুলভ ভঙ্গিমাটি আয়ত্ত করা। আই বি এমের প্রোজেক্ট ডিবেটারকে যদিও পরাজিত করলেন নামী তার্কিক হরিশ নটরাজন, কম্পিউটার যে নিজের বক্তব্যের সমর্থনে কত প্রাসঙ্গিক তথ্য পরিবেশন করতে পারে তা দেখে সবাই মুগ্ধ।
এতো হল কম্পিউটারের যুক্তি, তর্ক আর গল্প করার ক্ষমতা। মানুষের মতন চলে ফিরে কাজকর্ম করার ক্ষমতা এখনও রোবটের হয়নি। বেশিরভাগ পরীক্ষামূলক রোবট নিয়ন্ত্রিত পরিবেশে কাজ করতে পারে। বস্টন ডাইনামিক্স অবশ্য বেশ কিছু রোবট বানিয়েছে যাদের চলাফেরার দক্ষতা লক্ষণীয়। তবে আমাদের সাথে সহবাস করার মতন রোবট এখনও তৈরি হয়নি। একসময় নিশ্চয়ই তৈরি হবে। তখন কি গল্পের মতন এই অসীম শক্তিশালী রোবটের দল মানুষের উপর আধিপত্য করতে পারে? এ বিষয়ে অনেক জল্পনা করা যেতে পারে। তবে রোবটকে যতই মানুষের মতন বা তার চেয়েও শক্তিশালী ও দক্ষ বানাই না কেন, সে শুধু আমাদের আদেশ মেনে চলবে। এখনও মানুষের চেতনা ঠিক কি, তা আমরা বুঝি না। এই চেতনার আলোতেই আমাদের ভাললাগা, ভালবাসা, ইচ্ছা, উচ্চাশা, আবেগ, সৃজনশীলতা, এমনকি দুঃখ, হিংসা, ঘৃণাও। যতদিন রোবটের চেতনা না হচ্ছে, রোবট আমাদের দাস হয়ে থাকবে। আমরা নিরাপদ। কিন্তু একই কারণে রোবটের ব্যক্তিত্বে সেই সমৃদ্ধি আসবে না যাতে সে আমাদের প্রকৃত সখ্যের আনন্দ দিতে পারে, আস্থা অর্জন করতে পারে।
প্রচ্ছদের ছবি: এ আই এর উপর জাতিসঙ্ঘের এক আলোচনাচক্রে অংশগ্রহণকারী হিউম্যানয়েড রোবট সোফিয়া (ছবির সূত্র)
কিছু রেফারেন্স:
[১] Krizhevsky, Alex & Sutskever, Ilya & Hinton, Geoffrey. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Neural Information Processing Systems. 25. 10.1145/3065386.
[২] ‘Reinforcement learning: an introduction’ by Richard S. Sutton and Andrew G. Barto, MIT Press, 1992, 2018 (2nd Ed).